摘要
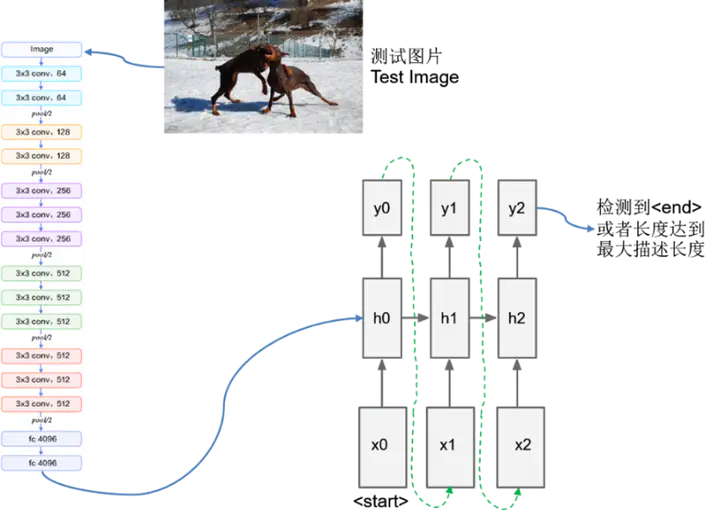
This paper aims to solve the problem of letting the computer automatically generate natural language descriptions corresponding to the content of an image, that is, letting the computer learn to “see and speak”, which is a fundamental problem in artificial intelligence that connects computer vision and natural language processing. This paper builds several end-to-end image captioning models by combining RNN especially LSTM with several deep convolutional neural networks, and performances are compared among models. All the models are belonged to the CNN+RNN architecture. The front convolutional neural network is used to extract the feature code from the input image, which is passed as input to the RNN decoder. All the models use the stochastic gradient descent algorithm to minimize the loss function and are trained end-to-end. The results on several datasets show that the models can learn to make the description more accurate. The final models are able to generate natural language descriptions according to the image content. Results on the Flisk8k dataset shows that the BLEU-1 of the one model reached 0.508, and the BLEU-2 reached 0.300, which exceeded some of the existing models. In addition, an application system is established Based on the image description models and details of models are shown by several data virtualization technologies.